


Als software engineer en oud-advocaat beweeg ik me dagelijks op het snijvlak van techniek en recht. Dat maakt me vaak tot vertaler tussen twee werelden die elkaar niet altijd goed verstaan. Nu tech steeds dieper de juridische wereld binnendringt, groeit de behoefte aan dat vertaalwerk. Deze artikelenreeks is daar een poging toe: technische begrippen ontleden die steeds vaker opduiken in gesprekken over legal tech. Niet om van iedereen een (tech)nerd te maken, maar om te helpen de juiste vragen te stellen (en de antwoorden te begrijpen).
We beginnen met RAG. Je hebt de term vast weleens gehoord, in een demo of een verkoopgesprek. Iedereen knikte. Maar wat betekent het eigenlijk?
Van gesloten naar open boek
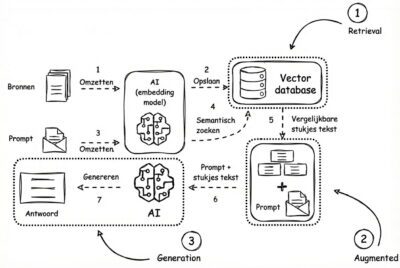
RAG staat voor Retrieval-Augmented Generation: een methode waarbij een AI-systeem eerst informatie ophaalt voordat het een antwoord formuleert.
Om te begrijpen waarom dat relevant is, moet je weten hoe een standaard AI-chatbot werkt. Bij een gewone ChatGPT-vraag gaat je prompt rechtstreeks naar het taalmodel. Die kennis is statisch: een momentopname van wat het model tijdens zijn training heeft gezien. Vraag je naar recente ontwikkelingen of interne documenten, dan krijg je in het beste geval ‘dat weet ik niet’. Maar vaker probeert het model behulpzaam te zijn en verzint het een onjuist antwoord dat ontzettend overtuigend klinkt.
RAG doorbreekt die beperking door het proces in drieën te knippen.
Stap 1: Retrieval (ophalen)
Je vraag gaat niet meer rechtstreeks naar het taalmodel, maar eerst naar een zoekmachine die relevante passages ophaalt uit een vooraf bepaalde bibliotheek (zoals wetgeving, jurisprudentie of interne documenten).
Stap 2: Augmentation (verrijken)
Die gevonden fragmenten worden achter je oorspronkelijke vraag geplakt. Je initiële vraag wordt daarmee een uitgebreidere opdracht.
Stap 3: Generation (genereren)
Pas nu mag het taalmodel antwoorden, met een duidelijke instructie: baseer je alleen op de meegegeven fragmenten. De AI wordt dus niet slimmer. Hij krijgt alleen een spiekbriefje.
Een cruciaal punt: de AI wordt dus niet getraind op jouw documenten. Hij mag er alleen in lezen voordat hij antwoordt. Daardoor is het resultaat niet gebaseerd op vage herinneringen uit zijn training, maar op concrete, meegegeven (bron)teksten.
Het verschil laat zich het best vergelijken met een tentamen. Zonder RAG werk je met gesloten boek: je moet het doen met wat je hebt onthouden. Met RAG mag je je boeken en aantekeningen erbij houden.
Waarom juristen dit moeten begrijpen
Juridisch werk draait om (rechts)bronnen. Een AI die antwoorden verzint zonder bronvermelding is niet alleen onbruikbaar, maar ronduit gevaarlijk. De afgelopen jaren zijn er wereldwijd meerdere pijnlijke incidenten geweest waarbij advocaten processtukken indienden met compleet gefabriceerde uitspraken. Ook in Nederland komt dat inmiddels voor. En er zijn sterke aanwijzingen dat dit recent weer gebeurde bij de rechtbank Den Haag.
RAG biedt een oplossing. Door het taalmodel te koppelen aan rechtsbronnen krijg je antwoorden die zijn gebaseerd op concrete documenten. Omdat de bronpassages doorgaans in het antwoord worden geciteerd, kun je verifiëren waar het antwoord op gebaseerd is. Dat is precies wat juristen nodig hebben: herleidbaarheid en controleerbaarheid.
De juiste vragen stellen
Wanneer een leverancier zegt dat hun tool ‘werkt met RAG’, is dat in principe goed nieuws. Maar de kwaliteit hangt volledig af van de uitvoering. Een paar vragen die je zou kunnen stellen:
- Welke bronnen worden doorzocht? Alleen publieke wetgeving en jurisprudentie, of ook interne documenten?
- Hoe actueel zijn die bronnen? Continu bijgewerkt of een snapshot van vorige maand?
- Kan ik de bronpassages inzien? Zonder die transparantie mis je het belangrijkste voordeel.
Maar de vraag die de kenners stellen, gaat dieper:
- Hoe gaat het systeem om met de hiërarchie van bronnen? Jurisprudentie ontwikkelt zich. Herkent het systeem bijvoorbeeld dat een later arrest een eerdere uitspraak nuanceert?
Geen wondermiddel
RAG vermindert het risico op hallucinaties aanzienlijk, maar elimineert het helaas niet. Een volledig hallucinatievrije AI bestaat (vooralsnog) niet.
Daar zijn meerdere redenen voor, die de moeite waard zijn om te begrijpen. De bronnen zelf kunnen verouderd of onvolledig zijn: als een recente wetswijziging nog niet is verwerkt, kent de AI die ook niet. Het taalmodel kan bronnen verkeerd interpreteren of combineren: het krijgt bijvoorbeeld drie fragmenten uit verschillende uitspraken en moet die samenbrengen tot één antwoord. Als het de verbanden onjuist legt, kan het resultaat nog steeds fout zijn, zij het gebaseerd op echte bronnen. En de zoekfunctie kan simpelweg de verkeerde documenten ophalen.
Dat laatste verdient toelichting. Om te begrijpen waar het misgaat, moet je weten hoe zo’n zoekfunctie werkt. Zie het als een bibliotheek die niet op alfabet is gesorteerd, maar op betekenis. Documenten over bijvoorbeeld ‘gevaarzetting’ en ‘aansprakelijkheid’ liggen conceptueel in dezelfde hoek, ook als de exacte woorden verschillen. De computer zet teksten om in getallen en zoekt naar passages die statistisch het meest op je vraag lijken. Dat klinkt slim, maar dat valt voor juridische vragen wel mee. Twee teksten kunnen semantisch sterk op elkaar lijken en juridisch toch een heel andere strekking hebben.
Dit zou je een passage-loterij kunnen noemen. Het systeem vindt stukjes tekst, maar begrijpt niet hoe bronnen zich tot elkaar verhouden. Het kijkt naar ‘welke teksten hebben vergelijkbare thema’s en woorden?’ in plaats van ‘welke uitspraken verwijzen naar dit artikel, en hoe verhouden die zich tot elkaar?’. Dit is de grootste uitdaging van veel huidige juridische AI-systemen.
Naar een juridische plattegrond
Er zijn oplossingen in ontwikkeling. Sommige integreren in hun RAG een zogenoemde knowledge graph: een netwerk waarin relaties tussen wetten, artikelen en arresten expliciet zijn vastgelegd. Zo’n graph fungeert als een juridische plattegrond. Waar een standaard RAG-systeem je ‘ongeveer in de buurt’ van het juiste antwoord brengt, volgt een knowledge graph stapsgewijs de juridische verbindingen die een jurist ook zou volgen. Maar daarover meer in een volgend artikel.
De kern blijft: RAG is geen vervanging voor juridische kennis. Het verandert de AI van een orakel dat je maar op zijn woord moet geloven, naar een assistent die je verwijst naar de concrete bronnen (en daarmee controleerbaar wordt). De beoordeling van wat er uitkomt, blijft (gelukkig) mensenwerk.
Volgende keer: vectoren en embeddings, oftewel hoe een computer (juridische) teksten ‘begrijpt’ (zonder ze werkelijk te begrijpen).











")